
这几天体验了下kaggle,感觉和CTF类似的地方就是经常做的都是无用功。记录一下对泰坦尼克这个题的瞎折腾。
题目就是根据已有的信息预测这个人是否能生还。首先导入库和数据,观察下样本的情况
1 | import pandas as pd |
1 | <class 'pandas.core.frame.DataFrame'> |
可以看到age字段缺失了比较多,fare和embarked(登船地点)缺了几个,cabin(舱号)缺了非常多。感觉少的可以用众数中位数之类的补齐,年龄可以用其他特征拟合,至于缺了三分之二的舱号还是换个方法用吧。
之后可以先计算下各个特征的IV值,看一下哪些对结果影响比较大
1 | train <- read_csv('train.csv') |
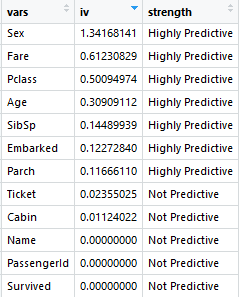
看到影响最大的是性别,很好理解,第二个因素是船票的价格emmm,有钱真好。还有就是Pclass也就是几号舱,年龄也有很大影响,小孩应该会先走,其他影响都不大。
直观的观察下各个特征与生存情况的关系,先定义一个画图的函数:
1 | mpl.rcParams['font.sans-serif'] = ['SimHei']//显示中文 |
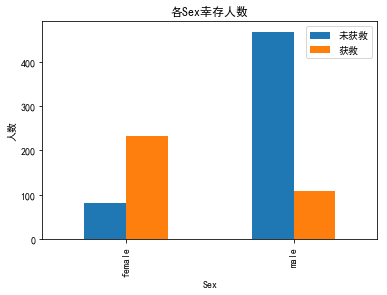
看下性别的影响,女性生还率特别高
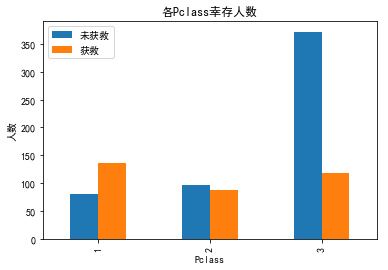
然后是一号舱也是正相关
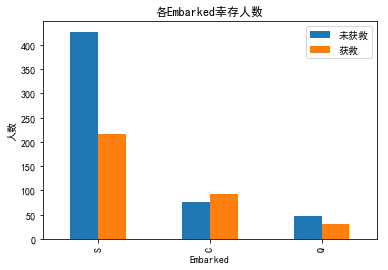
c港口登船的活下来的多一些
不过对于ticket和name两个字段也可以废物处理一下,虽然基本是没有规律的,但也有有规律的部分,比如名字中间的称呼可以提取出来,而ticket可以用来看看有没有用同一张联票的,这些人可能会在一起。
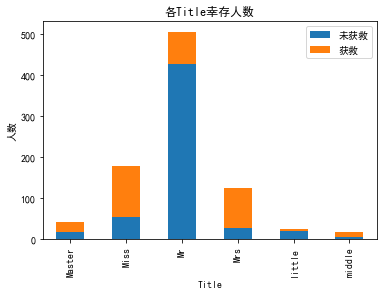
大致把称呼分成五个类,有些类别人数很少生还率差不多的就合并了
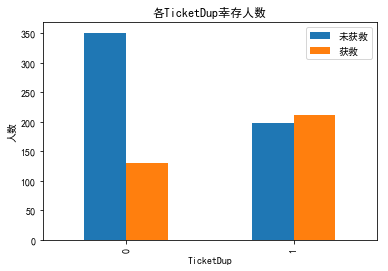
然后观察联票对生还率的影响,明显有联票的高一些,无依无靠还是很危险的
至于cabin字段,因为是否有记录本身也反映了一定信息,可能人死了就不知道具体船舱了。所以把无记录定义为一类,其他类根据第一个字母来划分。
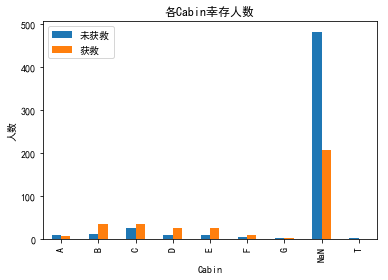
可以看到有记录的里面大部分还是活下来的多。
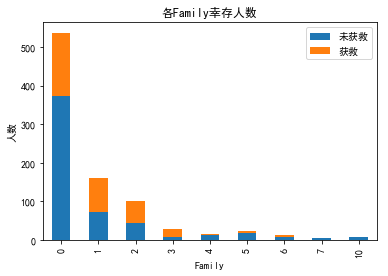
还有两个字段关于子女数兄弟数的,看了下趋势是相同的,合并成一个family字段,总体就是适中的生还率高,太少或者太多都有不利影响。
最后拟合年龄,选择用随机森林,当时想的是这个比较复杂,可能效果会比较好,其实也未必。
1 | from sklearn.ensemble import RandomForestRegressor |
然后fare和embarked的缺失值用中位数众数之类的填一下就行,缺的不是太多。这样特征基本就处理好了,下一步就是选择用什么模型。
因为是一个二分类问题,决定比较朴实的选择用逻辑回归做。那么对分类特征进行one-hot编码方便回归运算。然后把连续数值标准化,避免不收敛。标准化的时候应该把训练集和测试集分开,不然会有信息泄露。编码和标准化都有现成的方法,很简单。
直接逻辑回归算一下训练集准确率,看看有没有欠拟合
1 | from sklearn import linear_model |
1 | 0.8406285072951739 |
还不错,要是运气好点可能测试集也能有个80的准确率?(想多了)
然后计算测试集,结果存到csv,提交kaggle。结果是0.77511
针对训练好的模型可以做一下交叉验证,看看有没有明显的过拟合,这里还有个现成的可以画图的函数
1 | import numpy as np |

看着还可以。其实逻辑回归我也不知道还能调点什么,也就是再细分特征了,但感觉这已经很细了。。。
所以还是大力出奇迹吧,做个boost、bagging啥的模型融合,应该会有进步
1 | from sklearn.ensemble import BaggingRegressor |
因为我特征调了很多次,有时候bagging后结果有进步,有时候反倒下降了,感觉并不是万能的,还是跟特征选取有关。
这里之后就没有什么好办法改进,试了好几种模型,准确率都在75、76徘徊。从这张图上看还没有单纯只靠性别分准确率高,日
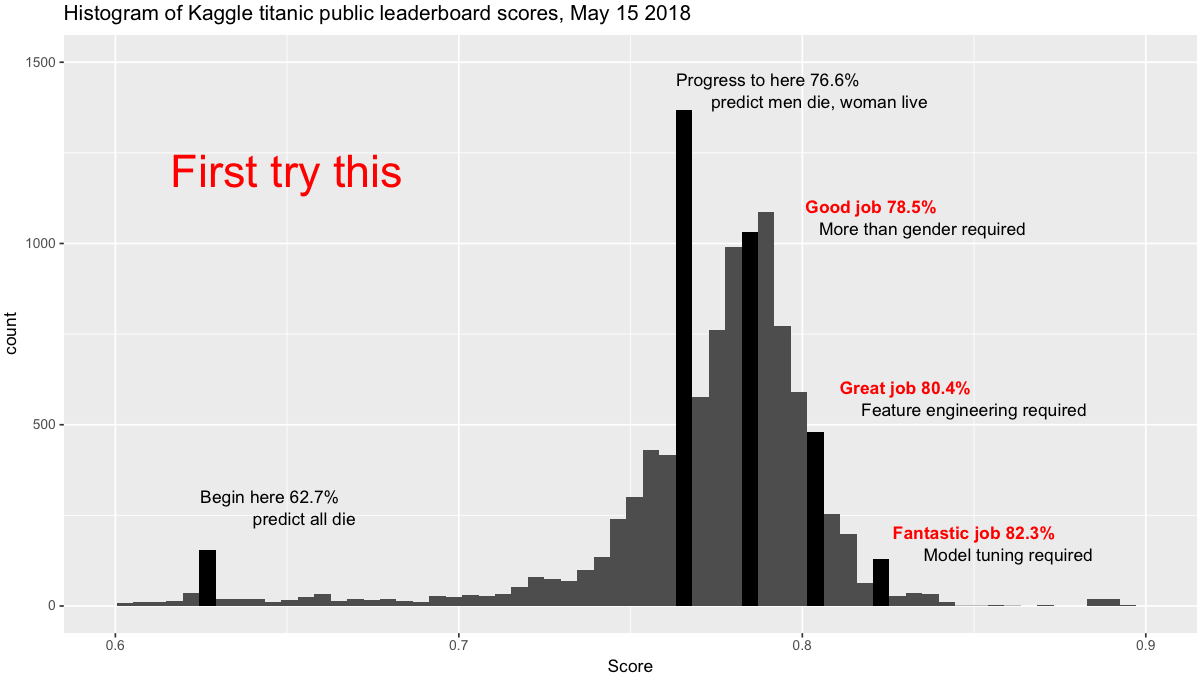
最后用到了gradientboosting梯度提升树,并且进行了艰苦的(玄学)调参,大部分时间也就跟逻辑回归一个结果。最后终于得到了进步,准确率到了0.799,排名1473/10113,排14.5%

折腾到这觉得可以告一段落了,就去看了看别人的kernel,结果发现了一些比较牛逼的东西
简单的分析最明显的特征,一个是性别,一个是pclass,还有一个是embarked。所以用一个手写的三层决策树(其实就是三个if)就可以做个简单预测:
先判断所有男性都没活下来
因为大部分女性都活了,但pclass=3的大部分人都死了,所以判断pclass!=3的女性都活了
然后对于pclass=3的,因为embarked=s的大部分人都死了,所以判断embarked!=s的女性都活了
其实也就是假设男性都死。女性除了pclass=3&&embarked=s的,都活。
1 | data_train['Surv'] = 0 |
这么两行的准确率是多少呢?0.7799(微笑)
还有一个准确率83还是85的模型,他只判断了两件事,一个是性别,另外就是这个人一家的人的生还状况(可以从name字段判断)。毕竟一家人就是要整整齐齐。
所以可以看出来,最重要的还是特征分析这步,再牛逼的模型也没办法代替人来提取相关的信息。因为人可以从正向来进行思考,当这件事发生的时候,当时的人是怎么做决策的,是不是会女士优先,小孩先走,一家人互相帮助,同生共死。而机器和模型只能从已有的数据中以偏概全的去还原。这点倒是挺值得思考的。
参考链接:
https://www.kesci.com/home/project/5bfe39b3954d6e0010681cd1
https://www.kaggle.com/ldfreeman3/a-data-science-framework-to-achieve-99-accuracy
https://www.kaggle.com/mauricef/titanic